A listener from our podcast, The Context, that Artem Zinnatullin and I run asked me, if I can give him an example of the Repository Pattern. So I googled around and stumbled upon some blog posts and found out that the term Repository Pattern is used and described in many different ways. In this blog post I want give you a brief history of the Repository Pattern and I want to discuss why I think the Repository Pattern could lead to over abstraction and over engineering.
Before we get started, I wanted to say that the term Repository Pattern is used and defined in different ways in different contexts and different programming languages. Therefore, I split this post into two parts: In the first part I want to discuss why I think the “original” definition of the Repository Pattern is an over engineered abstraction you very very rarely need and in the second part I want to show a common and popular definition of the Repository Pattern that may be a better choice for the average use case.
The original Repository Pattern
As far as I know the repository pattern was first introduced by Martin Fowler et al. in the book Patterns of Enterprise Application Architecture. This blog post by Krzychu Kosobudzki or this blog post Christian Panadero give an example of the usage of this pattern in the context of android development. In my opinion the original repository pattern is an over engineered abstraction layer you very very rarely need. Especially on Android. What do I mean with over engineered? Let’s have a look at the example from Krzychu Kosobudzki’s blog post:
interface Repository<T> {
void add(T item);
void remove(Specification specification);
List<T> query(Specification specification);
}
What is the Specification type? Basically Specification is just an interface like this:
interface Specification { }
interface SqlSpecification extends Specification {
String toSqlQuery();
}
Then we could have concrete Specification to query all list of News from SQLite database, ordered by date, like this:
class NewestNewsesSqlSpecification implements SqlSpecification {
@Override
public String toSqlQuery() {
return String.format(
"SELECT * FROM %1$s ORDER BY `%2$s` DESC;",
NewsTable.TABLE_NAME,
NewsTable.Fields.DATE
);
}
}
Another example of a Specification looks as follows:
public class NewsByIdSqlSpecification implements SqlSpecification {
private int id;
public NewsByIdSpecification(final int id) {
this.id = id;
}
@Override
public String toSqlQuery() {
return String.format(
"SELECT * FROM %1$s WHERE `%2$s` = %3$d';",
NewsTable.TABLE_NAME,
NewsTable.Fields.ID,
id
);
}
}
And then use that components like this:
public class NewsSqlRepository implements Repository<News> {
@Override
public List<News> query(Specification specification) {
SqlSpecification sqlSpecification = (SqlSpecification) specification;
SQLiteDatabase database = openHelper.getReadableDatabase();
List<News> newses = new ArrayList<>();
Cursor cursor = database.rawQuery(sqlSpecification.toSqlQuery());
for (int i = 0, size = cursor.getCount(); i < size; i++) {
cursor.moveToPosition(i);
newses.add(toNewsMapper.map(cursor));
}
cursor.close();
return newses;
}
}
Again, all code snippets shown above are borrowed from Krzychu Kosobudzki blog post.
Usually you use NewsRepository i.e. in your Presenter (MVP) or use case / interactor if you are following the clean architecture like this: newsRepository.query(new NewestNewsesSqlSpecification()).
So far so good. Before we continue, I want to ask you two essential questions:
First question: Why and when do we use the repository pattern? I want to link to the book Patterns of Enterprise Application Architecture by Martin Fowler et al.
The Repository will carry out the appropriate operations behind the scenes. Conceptually, a Repository encapsulates the set of objects persisted in a data store and the operations performed over them, providing a more object-oriented view of the persistence layer. Repository also supports the objective of achieving a clean separation and one-way dependency between the domain and data mapping layers.
Second Question: What are the benefits of abstractions like Specification?
- Single responsibility: This class is responsible to create a “criteria”. In the case of NewestNewsesSqlSpecification this criteria is translated to an SQL string.
- Hide implementation details: The SQL Statement is hidden in NewestNewsesSqlSpecification, so that no other class has to know about SQL at all.
- We can reuse Specifications: Imagine a Specification with a SQL WHERE clause. We could define such a Specification once and reuse it whenever we need a different WHERE clause based specification.
- Open / Closed principle: As Krzychu Kosobudzki pointed out correctly, this allows to create new specifications (and therefore new functionality) without having to touch something else in your code base.
What are the disadvantages with that extra abstraction layer? Well, now whoever calls newsRepository.query(new NewestNewsesSqlSpecification()) has to know which Specification to pass in. That is not a problem per se, but developers begin to over abstract that pattern. For example, Krzychu Kosobudzki says that with the repository pattern we can change concrete implementation as requirements changes. He gives the example of using Realm instead of SQLite database:
public class NewsRealmRepository implements Repository<News> {
@Override
public List<News> query(Specification specification) {
RealmSpecification realmSpecification = (RealmSpecification) specification;
Realm realm = Realm.getInstance(realmConfiguration);
RealmResults<NewsRealm> realmResults = realmSpecification.toRealmResults(realm);
List<News> newses = new ArrayList<>();
for (NewsRealm news : realmResults) {
newses.add(toNewsMapper.map(news));
}
realm.close();
return newses;
}
}
As you see there is another subtype of Specification for Realm:
public interface RealmSpecification extends Specification {
RealmResults<NewsRealm> toRealmResults(Realm realm);
}
public class NewsByIdSpecification implements RealmSpecification {
private final int id;
public NewsByIdSpecification(final int id) {
this.id = id;
}
@Override
public RealmResults<NewsRealm> toRealmResults(Realm realm) {
return realm.where(NewsRealm.class)
.equalTo(NewsRealm.Fields.ID, id)
.findAll();
}
}
The problem is that whoever calls newsRepository.query(…) has to know whether it has to pass in a NewestNewsesSqlSpecification or NewestNewsesRealmSpecification. So is it really that easy to change your implementation from SQLite to Realm? No, it’s not because you have to change the specifications everywhere from FooSqlSpecification to FooRealmSpecification. There is also one big code smell coming along with this:
@Override
public List<News> query(Specification specification) {
SqlSpecification sqlSpecification = (SqlSpecification) specification;
...
}
@Override
public List<News> query(Specification specification) {
RealmSpecification realmSpecification = (RealmSpecification) specification;
...
}
Whenever you are programming against an interface but you have to cast an interface to a concrete class, in 95% of the time you are doing something wrong!
Martin Fowler et al. didn’t make a statement about Repository Pattern and changing concrete implementation (i.e. SQLite to Realm). Fowler et al, described the repository pattern as
adding this layer helps minimize duplicate query logic.
So the original definition of the repository pattern is all about minimizing duplicate query logic and not necessarily to build an abstraction layer to change the underlying database.
I don’t want to blame anybody. This is not a Android related problem, we also see that quite often in Java EE world, especially in spring framework powered backends.
Evolution of the Repository Pattern term
In android development the term Repository Pattern is quite often used in combination with Clean Architecture. So did Fernando Cejas in his excellent blog post Architecting Android…The clean way? (scroll down to “Data layer” section). Interesting enough, he also links to the original definition of the Repository Pattern by Martin Fowler et al. However, Fernando Cejas says:
All data needed for the application comes from this layer through a Repository implementation (the interface is in the domain layer) that uses a Repository Pattern with a strategy that, through a factory, picks different data sources depending on certain conditions.
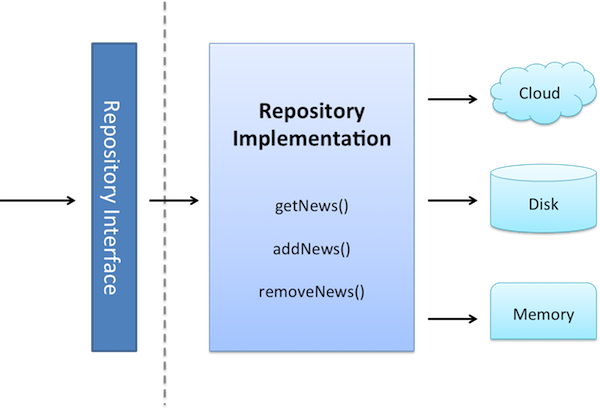
The idea behind all this is that the data origin is transparent for the client, which does not care if the data is coming from memory, disk or the cloud, the only truth is that the data will arrive and will be got.
As you can see here, the term Repository Pattern is used to describe something slightly different. You can see it even more clear if you check out Fernando’s Clean Architecture Sample Project on Github. In his sample he uses RxJava. For my blog post I have removed RxJava in the code snippets below for better understanding if you don’t have prior RxJava knowledge. I have also simplified the code a little bit to focus on the important things. For example Fernando wants to load an User by his id:
interface UserRepository {
User user(int userId);
}
The concrete implementation of that repository:
class UserDataRepository implements UserRepository {
private UserDataStoreFactory userDataStoreFactory;
@Override
public User user(int userId) {
UserDataStore userDataStore = userDataStoreFactory.create(userId);
return userDataStore.get(userId);
}
}
An UserDataStore is, as the name already suggests, responsible to load a User from a store like disk or a backend (cloud).
interface UserDataStore {
User getUser(int userId);
}
class DiskUserDataStore implements UserDataStore {
private DiskCache<Int, User> userCache;
@Override
public User getUser(int userId){
return userCache.get(userId);
}
}
class CloudUserDataStore implements UserDataStore {
@Override
public User getUser(int userId){
// Make an HTTP request and return User.
}
}
UserDataStoreFactory is the component that decides which UserDataStore to use when someone calls UserRepository.getUser(userId). For example the factory could check if DiskUserDataStore has a User and if the User object is expired then the factory returns CloudUserDataStore, otherwise DiskUserDataStore. The factory could also take into account if the smartphone has an active internet connection or not. I guess you get the point.
Conclusion
Fernando Cejas interpretation of the Repository Pattern is representative of other developers that nowadays interpret the Repository Pattern in a similar way. However, it has not much in common with the “original” definition of the Repository Pattern by Martin Fowler et al. Wasn’t the repository pattern meant to be used to minimizing duplicate query logic? Martin Fowler didn’t say anything about loading users from different UserDataStores. Where did the Specification class go?
If you compare both, the original Repository Pattern and the later one, you will see that actually they are trying to solve two different kind of problems. While the original one tries to minimize duplicate query logic (by open / closed principle) the later one tries to hide the concrete data store your app is talking to. But from my point of view you can’t really solve both problems at the same time within the same pattern as Krzychu tried in his blog post by adding another abstraction. You have to choose which problem you actually want to solve (you can chain both patterns together though).
So why are both patterns called Repository Pattern? This happens quite often in history. A name gets (re)used for different purpose. For example Trygve Reenskaug introduced Model-View-Controller in the 1970s but his definition has nothing in common with what we nowadays call MVC, i.e. describing Activities as Controller on android, UIController on iOS, Controller in backends and so on. The same happened to the term Repository Pattern.
No worries, evolution is good. We should just remember where we came from and why it has evolved to what it is used now, for better understanding where we are going. The original Repository Pattern was designed for Enterprise Applications to reduce duplication of query logic. Usually, your android app is not a enterprise application. Normally, in your android app you should follow Fernando Cejas definition of the Repository Pattern because mostly you want to hide the underlying data store implementation to be more flexible for future requirement changes and consequential refactoring.
But, if you take a closer look at the later interpretation of the Repository Pattern you will come to the conclusion that basically it just says: program against an interface so that you can change implementation details later and follow the single responsibility principle. That’s what all the Clean Architecture and Repository Pattern blah blah is about.
Don’t over abstract. Don’t over engineer. For example, if you start an app from scratch, yes, you should define an interface like UserRepo and all your business logic or domain layer or whatever layer should program agains this interface. However, if you only have one backend to load data from, then your UserRepo implementation should make these http calls directly in a concrete UserRepo class implementing the UserRepo interface. No need for UserDataStore, CloudUserDataStore and UserDataStoreFactory.
You may ask yourself: What if one day my requirements change and I have to use Realm instead of SQLite. Then you provide UserRepoRealm implements UserRepo instead of UserRepoSql implements UserRepo. Still no need for UserDataStore and UserDataStoreFactory. My message here is: build the minimal piece of code you really need and don’t over engineer it with requirements that may or may not be needed in the future. Seriously, I’m working in this industry for quite some years now and I have never worked on a backend, not to mention an android app, that has ever changed the underlying database. Don’t build an abstraction layer like SqlSpecification with such future requirements changes in mind. If one day you have to add something like a DiskCache along your cloud backend to communicate with, then it makes sense to refactor your code to respect the single responsibility principle and add classes like UserDataStoreFactory, UserDataStore, DiskUserDataStore and CloudUserDataStore. Since all your other layers are programming agains UserRepo interface, refactoring that is no problem at all.
Until then, no need for all this abstractions.